

Building a modular active learning framework
The feature roadmap of modAL for 2022


Data >> algorithms
According to Wikipedia, active learning "is a special case of machine learning in which a learning algorithm can interactively query a user (or some other information source) to label new data points with the desired outputs."
I find this idea extremely exciting. Investigating trained models to reveal blind spots in their knowledge is a brilliant idea, with the promise of building high-quality datasets suited to overcome real-life challenges like concept drift, open-set recognition, and many more. In my experience, a well-engineered training dataset means the difference between success and failure. Data >> algorithms.
In 2017, I created modAL, a small Python framework with a big vision: to fully modularize active learning pipelines, enabling both machine learning researchers and practitioners to engineer better data.
Five years passed by, and meanwhile, active learning had more exciting developments than I could keep track of. It is finally time to realize this vision and bring the field to the next level.
I am rebooting modAL, building a community of active learning researchers and practitioners, and I want you to be a part of it.
A high-level overview of active learning
The premise of active learning is simple: it creates a feedback loop between oracles and models, asking questions about unlabelled data to enhance predictive performance—models query, oracles answer. The entity answering the questions might even be algorithmic, like a deterministic function that is expensive to evaluate. So, the queries must be carefully selected to use the available resources optimally.
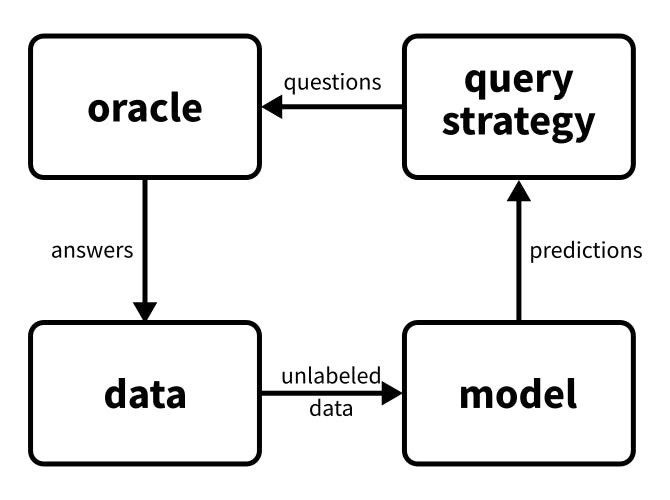
If we abstract away all the concrete details, there are four essential building blocks of such a feedback loop:
- the model,
- the oracle,
- the data,
- and the means of interaction between these three.
There are multiple possible components and environments. Models can range from linear regression to state-of-the-art convolutional networks, and in practice, the choice of the framework also complicates the situation. Is the unlabelled data streamed, or is a large sample pool available? There might not even be any data at all, just a large parameter space.
As components are diverse and might be across multiple frameworks such as PyTorch and TensorFlow, prototyping and building active learning pipelines require a lot of boilerplate code, slowing down the experiments. Replacing components quickly is essential to test out and build workflows. So far, this is unsolved in the field.
I want to build a framework that
- makes building active learning pipelines easy,
- interoperable with the major machine learning/deep learning frameworks (scikit-learn, PyTorch, TensorFlow),
- easy to extend with models/query strategies,
- and boosts active learning research and practice with ease of use.
Let's see what the technical challenges to overcome are!
Implementation intricacies
To illustrate the incompatibility issues in an active learning pipeline, let's take a quick look at the data. A dataset can take the form of a
- NumPy array,
- Pandas dataframe,
- PyTorch tensor,
- TensorFlow tensor,
and many more. Although the interfaces are similar, there are crucial differences down the line. For instance, the indexing operator [] on Pandas DataFrames uses columns-first indexing, while the others use rows-first.
However, not all data sources are compatible with all models. Some, like scikit-learn, are less restrictive, while deep learning frameworks are strict about their inputs. There are problems even between TensorFlow and PyTorch, like using the batch-first or batch-last format.
These problems are just the tip of the iceberg. Since the interface of the predictive models is not uniform, there is no way to write query strategies that can handle any of them in a framework-agnostic manner.
This slows down experimentation and method development in active learning significantly. If you have experience in deep learning, you know that training a model is far from an exact science, and you need to try different methods fast. Having to rewrite the entire pipeline from scratch just because you want to try a different model is not the way to go.
modAL roadmap
modAL was an early attempt to solve these problems, but as I mentioned, active learning has come a long way since then. (Not to say about my software development skills.) In 2017, classical methods were prevalent, so I decided to build modAL on top of scikit-learn.
From a design perspective, this was a good choice, as the scikit-learn API is excellently designed. On the other hand, it made integrating new and rising frameworks like Keras or PyTorch difficult. Currently, using Keras and PyTorch relies heavily on external scikit-learn wrappers, which is suboptimal. Users have to wrap their models manually, increasing the work they need to do.
Thus, the first on the roadmap is a refactor of modAL's core structure, adding internal wrappers for various machine learning frameworks and dataset formats.
This will enable us to work with models and data using a unified interface, leading to easy implementation of abstractions for active learning scenarios such as pool-based or stream-based active learning. Hence, the second step is to add Environment classes, responsible for controlling the feedback loop between the oracle and the model.
In the long term, I have two more goals. First, I would like to fix the tests and provide documentation that reads like a hands-on textbook about active learning. Second, my long-term goal is to integrate modAL into interactive data labeling applications, building valuable tools for practitioners.
To summarize, this is the planned roadmap.
- 2022 Q1: lightweight wrappers for the major machine learning frameworks and data sources (NumPy, Pandas, TensorFlow, PyTorch, scikit-learn, XGBoost, and others).
- 2022 Q2: abstractions for handling any active learning scenario (pool-based, stream-based, active optimization, etc).
- 2022 Q3-Q4: 100% test coverage and documentation that reads like an awesome active learning textbook.
- 2023: interactive and visual annotation tools, powered by modAL.
Development updates
If you are interested in development updates or want to contribute, sign up to the modAL newsletter, where I'll only post development updates and technical reports. 100% modAL development and active learning, 0% fluff or marketing.